

PythonでPDFの操作を行うライブラリについて解説してます。
今回ご紹介するライブラリは、django-wkhtmltopdfやPdfKit、WeasyPrintといったHTMLからPDFに変換するモノです。
他にもコードからPDFに変換するLeportLabについても説明しています。
PyPDF2とpdfminerやPDFの追記ができるpdfrwについては細かくは解説していません。
理由として開発が止まっているので、会社で保有のサービスに組み込むのは、保守やメンテナンスとしてのデメリットが大きと思ったので紹介していません。
他にもPythonでいろいろなファイルの読み書きを解説しています。
ご興味があれば、下記の記事もご覧ください。
-

-
Pythonでいろんな種類のファイルを操作方法を解説
Pythonを使って、テキストやJSON、YAMLといったさまざまなファイルの読み書きに関してピックアップしてみました。 調べてみてわかったことは、ほとんどのモジュールが書き込みと読み込みで同じような書き方になっていました。 そのため、数種 ...続きを見る
PDFとは

PDFとはPortable Document Format(ポータブル ドキュメント フォーマット)の略で、デバイスに依存せずに文章やイメージといった表示が崩れることなく表示することができる形式です。
PDFでは2種類の状態があり、イメージ画像としての構造とテキストなどを認識することができるOCRの状態を保持することができます。
以前までは、プリンターとか写真とかで撮ったデータは文章化するのが困難でしたが、AIなどのディープラーニングの発達によりイメージから文字を認識できるようになってきました。
ですが、まだまだ精度は高いとは言えません。
OCRについて
HTMLやWord、ExcelといったデータからPDF化を行うと、テキストや数値を光学文字認識することができます。
それがOCRです。
Pythonで利用できるPDF操作ライブラリ

今回 HTMLからPDF化を行う方法とコードからPDFを行う方法のライブラリを紹介します。
下記は、HTMLからPDFとコードからPDFなど、PDFを操作ができるライブラリです。
ライブラリ
- django-wkhtmltopdf
- PdfKit
- WeasyPrint
- reportlab
- pdfminer
- PyPDF2
- pdfrw
HTMLからPDF化
HTMLからPDF化とは、HTML構造のWebページであればPDF化を行うことができます。
ライブラリによっては、JavaScriptを認識して表示した内容をPDF化することもできます。
手軽にHTMLからPDFを作成するツールがwkhtmltopdfです。
このツールを利用したライブラリは、PythonだけじゃなくてNode.jsやPHPなど他の言語にもあります。
HTMLからPDF化を行うPythonのライブラリは下記になります。
HTMLからPDF化
- django-wkhtmltopdf
- pdfkit
- WeasyPrint
コードからPDFを生成
X軸やY軸といった指定により、文字や画像などの配置を行うことができます。
ReportLabがそれにあたります。
コードからPDF化
- ReportLab
django-wkhtmltopdfの使い方

django-wkhtmltopdfを利用するには、PythonのWebフレームワークのDjangoとwkhtmltopdfのインストールが必要になります。
今回は、Djangoがインストールされている前提で説明します。
wkhtmltopdfのインストール
django-wkhtmltopdfとは別に、HTMLをPDF化を行う本体のwkhtmltopdfのインストールが必要になります。
すでにインストールされているのであれば、飛ばしてください。
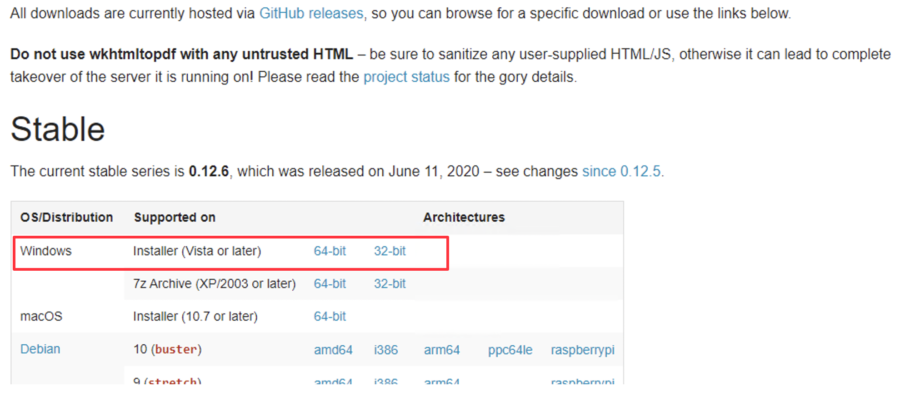
Windowsの場合は、インストーラーからインストールします。
インストーラーは、公式サイトからダウンロードしてください。
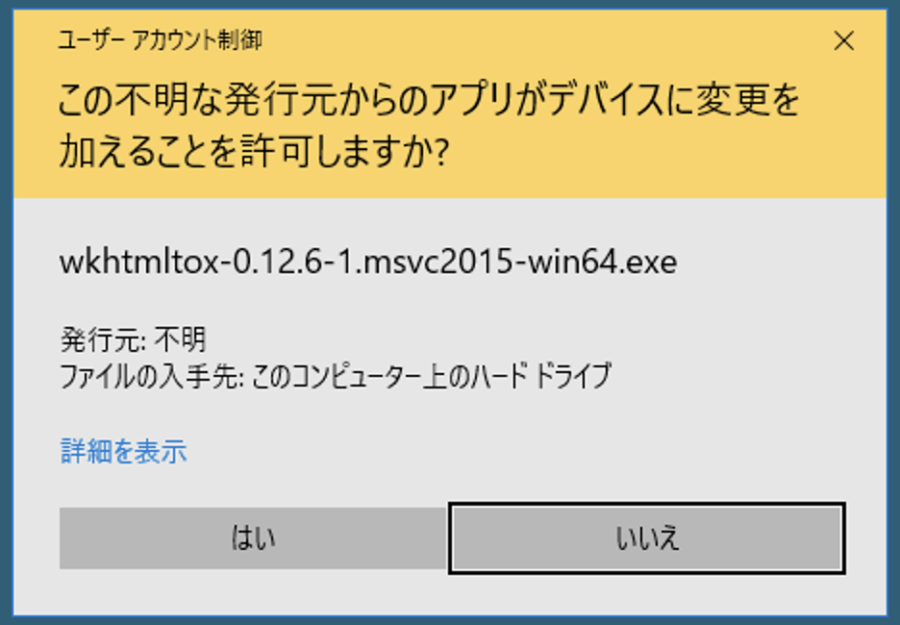
ダウンロードが完了すると実行してください。
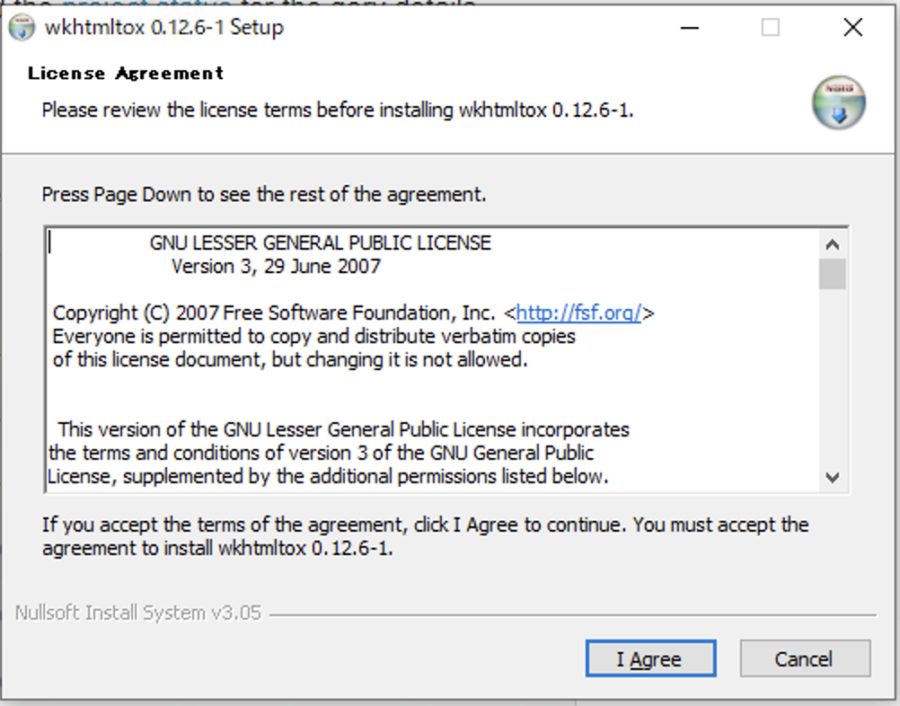
実行許可とライセンスの同意が求められるので、「はい」と「I Agree」をクリックします。
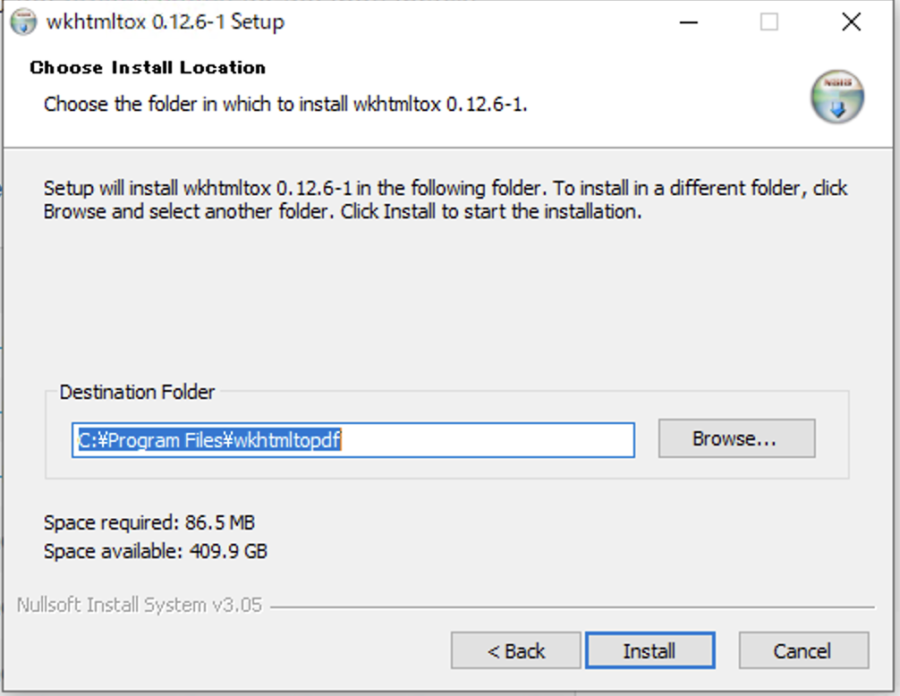
インストールの場所を求められるので、変更がなければ「Install」ボタンをクリックしてインストールします。
下記の画面が表示されるとインストールが完了になるので、「close」ボタンをクリックして終了してください。
Macの場合は、Home Brew を使ってインストールします。
$ brew install wkhtmltopdfdjango-wkhtmltopdfのインストール
インストールするには、pipを使います。
下記コマンドをWindowsとMacで実行してみましたが、問題なくインストールすることができました。
$ pip install django-wkhtmltopdfwkhtmltopdfの設定
Djangoの設定ファイルのserttings.pyに2つの行を追加します。
追加項目
- WKHTMLTOPDF_CMD
- STATIC_ROOT
追加の例は下記になります。
WKHTMLTOPDF_CMD='/usr/local/bin/wkhtmltopdf'
STATIC_ROOT='/Users/ユーザ名/プロジェクト/to/Djang/パス/static'WKHTMLTOPDF_CMDは、wkhtmltopdfのコマンドがどこにあるか指定します。
そのため、Macの場合は下記のコマンドで場所を確認してください。
$ which wkhtmltopdf実行するとコマンドの場所を確認できますが、表示されなかった場合はインストールされていません。
Windowsの場合は、C:\Program Files\wkhtmltopdf\bin\wkhtmltopdf.exeにあります。
STATIC_ROOTは、Djangoのstaticパスを指定したり、テキトーにstaticパスを作成して追加すると動きます。
実行
Djangoの設定も完了したので、HTMLからPDFを生成するためにDjangoのViewにwkhtmltopdfを設定します。
from wkhtmltopdf.views import PDFTemplateView
class PdfSampleView(PDFTemplateView):
filename = 'sample.pdf'
template_name = "index.html"filenameはPDFのファイル名になり、このViewをルーティングで設定します。
実際のHTMLのコードは下記になります。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>サンプル</title>
</head>
<body>
<h1>Djangoでwkhtmltopdf</h1>
</body>
</html>
設定したルーティングのURLにアクセスすると、PDFのダウンロードが始まります。
下記がそのPDFになります。
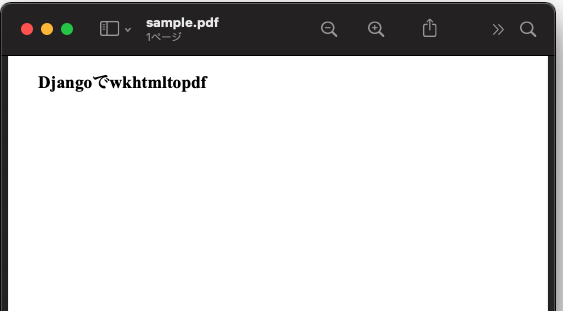
文字化けもせずに表示されました。
Pdfkitの使い方

Pdfkitは、URLやHTMLファイル、文字列からPDFを生成します。
一部でHTMLなどを利用しているため、Pdfkitもwkhtmltopdfを利用します。
wkhtmltopdfのインストールの仕方については、django-wkhtmltopdfのセクションにあります。
Pdfkitを使うメリットは、Djangoなどのフレームワークを準備することなく利用することができる点です。
HTMLをPDF化するのに、わざわざDjangoとか入れるのはめんどくさい。
そういった場合に、Pdfkitを使います。
Pdfkitのインストール
Pdfkitをインストールするには、pipコマンドからインストールします。
$ pip install pdfkitHTMLファイルからPDF化
HTMLファイルからPDFを作成します。
まずは、HTMLファイルを作成します。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>PDF作成</title>
</head>
<body>
<h1>PdfKitでPDFを作成します</h1>
</body>
</html>次に、HTMLからPDFにするためのPythonファイルを作成します。
HTMLからPDFにするには、from_file関数を使います。
import pdfkit
pdfkit.from_file('./sample.html', 'out.pdf')これだけで、HTMLからPDFを作成することができます。
実際に実行すると下記のPDFファイルが作成されます。
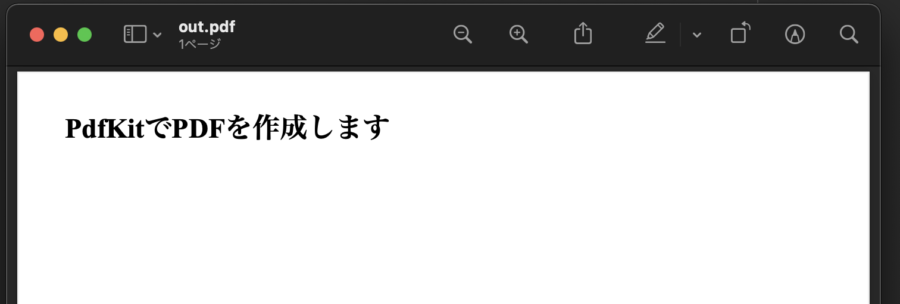
URLで別サイトをPDF化
URL先のサイトをPDF化することができます。
これもHTMLからPDF化と同じようにカンタンに実装することができます。
利用する関数は、from_url関数になります。
import pdfkit
pdfkit.from_url('https://google.com', 'google.pdf')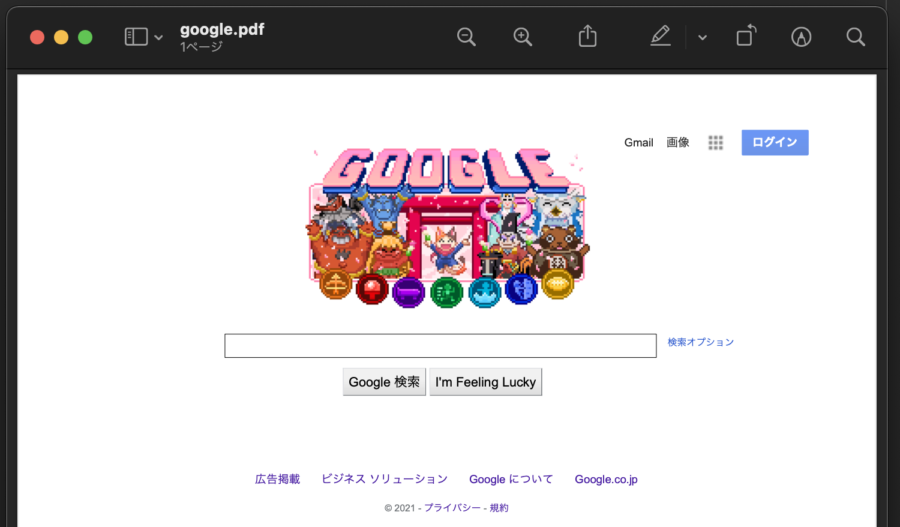
文字列からPDF化
文字列からPDF化を行うことができます。
この場合、from_string関数を利用します。
import pdfkit
pdfkit.from_string('<html lang="ja">'
'<head><meta charset="utf-8"></meta></head>'
'<body><p>文字をPDF化</p></body></html>', 'str.pdf')単純な文字を入れてPDF化することもできますが、日本語は文字化けします。
そのため、対策としてHTMLを文字列として書いて、metaタグで文字コードをセットしています。
WeasyPrintの使い方

WeasyPrintとは、シンプルなHTMLからさまざまなデザインを適用させ、PDFレポートなどを作成することができます。
WindowsやMac、Linuxで動作します。
WeasyPrintは、wkhtmltopdfを利用せずWeastPrintのエンジンを使っているようです。
WeasyPrintのインストール
Windowsでは、現状インストールの際にエラーがでて解決できていないので実行はしないでください
Windowsにインストールす場合
Windowsにインストールする場合、公式サイトでは難しい可能性があると書かれていました。
GTK3のインストールが必要なので、Githubからダウンロードします。
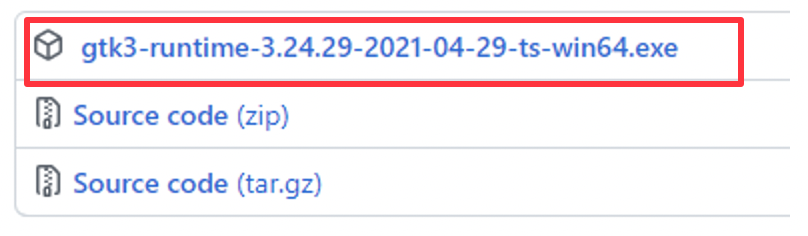
WeasyPrintのインストールを行います。
python -m pip install weasyprint下記コマンドで確認してみます。
python -m weasyprint --info下記のエラーが出ました。
OSError: cannot load library 'gobject-2.0-0': error 0x7e. Additionally, ctypes.util.find_library() did not manage to locate a library called 'gobject-2.0-0'
色々試してみたのですが、インストールできませんでした。
解決したら追記します。
Macにインストールする場合
libffiとpangoが必要とのことで、Home Brewを使ってインストールします。
$ brew install pango libffi次に、WeasyPrintをpipコマンドを使ってインストールします。
$ pip install weasyprintインストールできた確認のために、下記のコマンドを実行します。
$ weasyprint --info下記の内容が出ていたらインストール成功です。
WeasyPrint version: 53.2
Python version: 3.9.6
Pydyf version: 0.1.1
Pango version: 14809実際に動かしてみる
実際に動かしてみます。
コード自体も、PdfKitと同じでカンタンに記載できます。
Googleのページを読み込んでみます。
from weasyprint import HTML
HTML('https://google.com').write_pdf('./weasyprint_sample.pdf')ローカルのHTMLを読み込む場合は、HTMLにURLではなくファイルパスを指定できます。
from weasyprint import HTML
HTML('./sample.html').write_pdf('./weasyprint_html_sample.pdf')結果は下記になります。
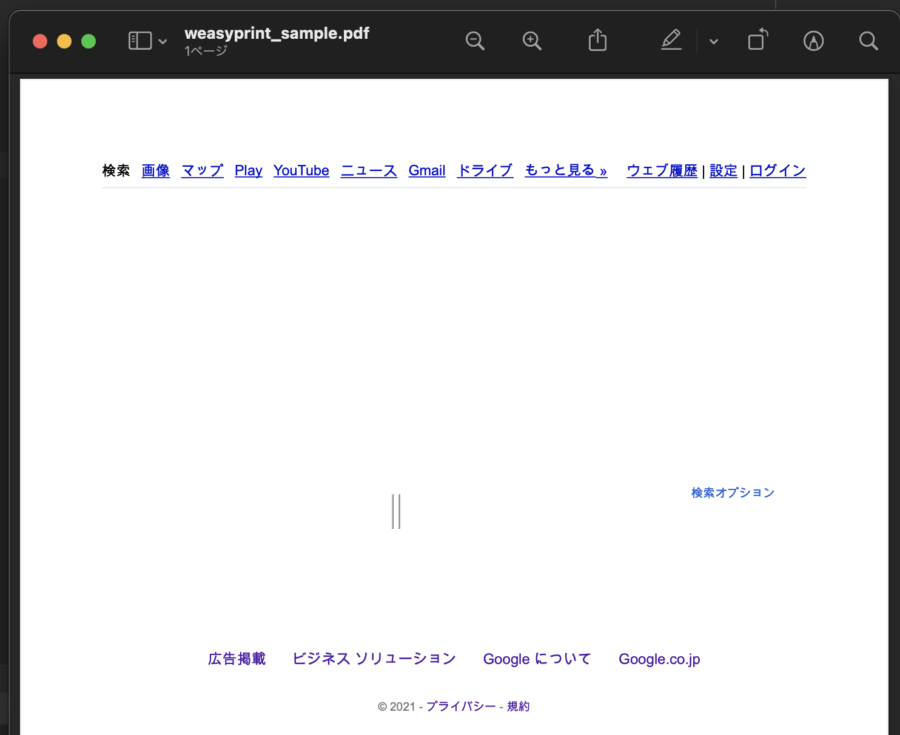
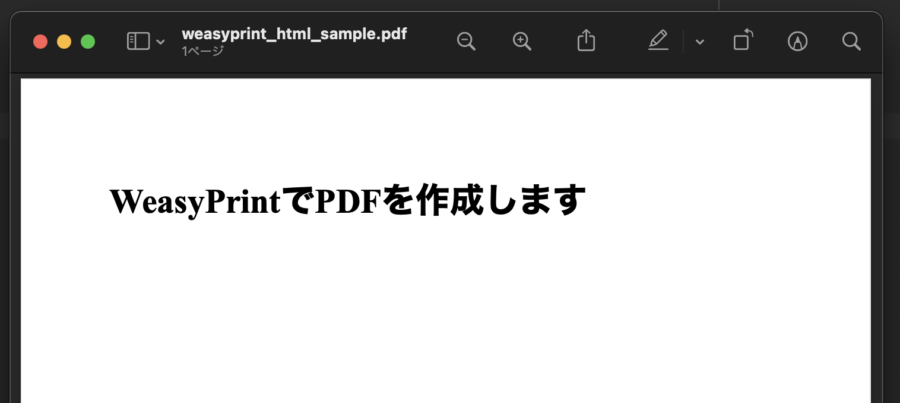
Googleの検索画面を表示しましたが、検索フォームがうまく表示できませんでした。
ローカルにあるHTML関しては、単純な構造のHTMLだったのうまく表示できていますが、CSSとかを絡めるとうまく表示できない。
reportlabの使い方

ReportLabは、ReportLab Open SourceとReportLab Plusがある。
Plusの方は有料版で、Open Sourceの方は無料版となっている。
ここで解説するのは、Open Sourceの方です。
reportlabのインストール
インストールするには、pipコマンドを使いますが、Repositoryからダウンロードすることもできます。
下記コマンドで、WindowsとMacで試しましたが問題なくインストールできました。
$ pip install reportlabPDFの作成
ReportLabでPDFを実際に作成してみます。
from reportlab.pdfbase import pdfmetrics
from reportlab.pdfbase.cidfonts import UnicodeCIDFont
from reportlab.pdfgen import canvas
def WritePDF(c):
c.drawString(0, 500, "Hello World サンプル")
c = canvas.Canvas('reportlab.pdf')
pdfmetrics.registerFont(UnicodeCIDFont('HeiseiMin-W3'))
c.setFont('HeiseiMin-W3', 20)
WritePDF(c)
c.showPage()
c.save()registerFontで日本語フォントを登録します。
次にsetFontで指定することで、日本語フォントを利用しています。
そうすることで、PDFの文字化けが改善されます。
結果は下記になります。
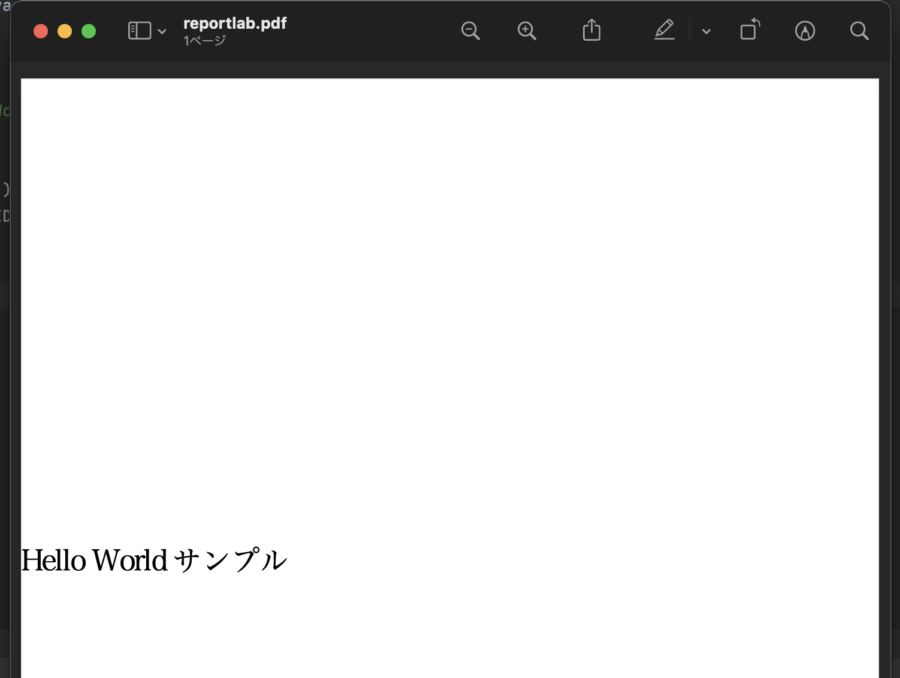
drawStringで文字を設定していますが、X軸とY軸が0の時は左上ではなく左下が0の位置になります
PyPDF2とは

PyPDF2は、文章の抽出や文章の分割、結合、切り抜きなどを行うことができます。
開発が2016年の5月で止まっているので、オススメはできないです。
そのため、メンテナンス性などを考えると、どういった機能があるのか把握するだけにとどめた方が良さそうです。
pdfminerとは

pdfminerは、PDFファイルからテキストを抽出するためのモジュールです。
こちらも開発が2019年11月と止まっているので、紹介だけにします。
PDFに追記
PDFに追記をするには、pdfrwモジュールを使います。
こちらも開発が2017年9月で止まっています。
こちらも紹介だけにします。
使い方としては、pdfrwでPDFを読み込んでReportLabで追記する処理になります。
まとめ
django-wkhtmltopdfでは、Djangoのフレームワークを利用しているなら利用した方が良いでしょう。
しかし使っていない場合は、DjangoのインストールとかめんどくさいしDjangoへの学習コストが増えるので、HTMLからPDF化を行うならPdfKitを使った方が無難です。
WeasyPrintについては、Windowsにインストールするのにうまくいきませんでした。
Windowsにインストールするには、クセがあるようです。
他にもCSS関連の表示がうまくいかなかったので、WeasyPrintを利用するのは避けた方が良いかもしれません。
あとは、PDFの結合やテキスト抽出といった読み込み系のPyPDF2やpdfrw、pdfminerについては2021年9月時点で確認しましたが開発が止まってます。
機能としては使えますが、今後の開発に支障が出そうなので使い方については、この記事では紹介していません。
更新されていないライブラリを使うと、どの開発言語問わず大幅なアップデートで使えなくなり、既存のサービスなどに影響を及ぼす可能性があります。
そんな痛い目に遭わないようにするために、利用しない方が良いでしょう!
どうしてもPDFの文字抽出系を行いたいなら、TesseractやPyOCRを使った方がまだ良いです。
他にもPythonでいろいろなファイルの読み書きを解説しています。
ご興味があれば、下記の記事もご覧ください。
-
-
Pythonでいろんな種類のファイルを操作方法を解説
Pythonを使って、テキストやJSON、YAMLといったさまざまなファイルの読み書きに関してピックアップしてみました。 調べてみてわかったことは、ほとんどのモジュールが書き込みと読み込みで同じような書き方になっていました。 そのため、数種 ...続きを見る

今後の人生を豊かにする為にキャリアアップのステップとして、自分への投資をしてみませんか?