

Pythonでエクセルの操作をして、集計表や分析するために色々作っていました。
今回、日本取引所が出している日本株一覧表のデータを自動で取得するために、GolangのSeleniumで作るのがめんどくさかったのでPythonで作ることにしました。
正直、SeleniumじゃなくてScrapyやもっとカンタンにできるのですが、PythonのSeleniumは使った事がなかったので試しに作成してみました。
この記事では、PythonのSeleniumについて解説しています。
ちなみに、GolangでSeleniumを使って作るとなると、情報量が少なく最初作った時は結構大変だった記憶があります。
Seleniumとは

Selenium(セレニウム)とは、Webアプリケーションをテストするためのオートメーションツールです。
本来はテストするためにブラウザの操作を自動化するものなのですが、最近ではWebスクレイピングなどで使われる事が多い気がします。
Webスクレイピングとは
スクレイピングとはデータを収集する技術のことを指し、WebスクレイピングはWebサイトの情報を集めることになります。
Pythonで利用できるWebスクレイピングのライブラリ

PythonでWebスクレイピングをする事ができます。
クローラーだけであれば、BeautifulSoupといライブラリもあるのですが、Webスクレイピングの代表的なものがScrapyです。
Scrapyは実装や運用するための機能を持つ、クロールフレームワークになります。
日本株一覧を実際に取得してみました

JPXの日本株一覧の取得上、別にScarpyやHttpによるリクエスト処理で取得も可能ですが、Seleniumを使って作成していきます。
Seleniumライブラリのインストール
Pythonにあるpipコマンドを利用して、Seleniumをインストールします。
下記がそのコマンドになります。
$ pip install seleniumドライバーのダウンロード
Seleniumを使うには、利用したいブラウザのドライバーが必要になります。
ChromeやFirefox、Edgeで利用する事ができますが、今回はChromeドライバーをダウンロードします。
Chromeドライバーのサイトから、自身のブラウザのバージョンにあったドライバーをダウンロードします。
そうしないと、動かないです。
ちなみに、自分が使っているChromeのバージョンを調べる方法は、右上にある「・・・」が縦に並んでいるアイコンをクリックして「ヘルプ」->「このGoogle Chromeについて」の順にクリックするとバージョンを確認する事ができます。


私のバージョンでは、「95.0.4638」だったのでChromeドライバーの95系のバージョンをダウンロードしたら動きます。
ドライバーの読み込み
Seleniumでドライバーを読み込むことで、ブラウザが起動します。
Chromeを呼び出す場合は、下記になります。
from selenium import webdriver
driver = webdriver.Chrome()Firefoxだと下記になります。
from selenium import webdriver
driver = webdriver.Firefox()Edgeだと下記になります。
from selenium import webdriver
driver = webdriver.Edge()この呼び出し方は、所定の場所にドライバーがインストールされていないとエラーが表示されます。
Chromeでは、「Message: 'chromedriver' executable needs to be in PATH」になり、Firefoxだと「Message: 'geckodriver' executable needs to be in PATH.」、Edgeだと「msedgedriver' executable needs to be in PATH.」が表示されます。
そのため他のサイトではドライバーの指定をして説明しています。
上記のドライバー呼び出しに対してexecutable_pathを引数にドライバーを設定して説明していますが、これは古いやり方になります。
Selenium4のバージョンからは、executable_pathではなくserviceを引数に設定します。
下記は従来のやり方です。
from selenium import webdriver
driver_path = 'chromedriver'
driver = webdriver.Chrome(executable_path=driver_path)
これを実行すると下記のWarningが表示されます。
DeprecationWarning: executable_path has been deprecated, please pass in a Service object
driver = webdriver.Chrome(executable_path=driver_path)動かなくなるわけでは無いのですがWarningが表示されて気持ち悪いので、このWarningを消すためにServiceを使ってドライバーを指定します。
Serviceを使ったドライバーの指定は下記になります。
from selenium import webdriver
from selenium.webdriver.chrome import service
driver_path = 'chromedriver'
chrome_service = service.Service(executable_path=driver_path)
driver = webdriver.Chrome(service=chrome_service)この様に呼び出すことで、「DeprecationWarning」という表示が消えます。
タイムアウトの設定
個別にタイムアウトの設定もできるのですが、一括でタイムアウトの設定をします。
WebDriverWaitを使えば、タイムアウトができると調べて書かれているのですが、私の環境ではどうしてもWaitしている感じがしなかったので、sleepを使おうとしました。
でも下記の様にしたら、うまくいったので掲載します。
from selenium import webdriver
from selenium.webdriver.chrome import service
from selenium.webdriver.support.wait import WebDriverWait # 追加
driver_path = 'chromedriver'
chrome_service = service.Service(executable_path=driver_path)
driver = webdriver.Chrome(service=chrome_service)
# ここから追加
TIMEOUT = 60
driver.implicitly_wait(TIMEOUT)
wait = WebDriverWait(driver=driver, timeout=TIMEOUT)WebDriverWaitをインポートします。
ここから追加の部分からの説明ですが、implicitly_waitで指定した要素が見つかるまで待機させます。
WebDriverWaitを使って、タイムアウトのインスタンスを呼び出して、全体なのか一部なのか指定する事ができます。
ページを表示
URLを指定して、ページを表示させます。
ページを表させるのはとてもカンタンで、getを使うだけです。
driver.get(URL)下記は、Googleの検索ページを表示する例です。
url = 'https://google.com'
driver.get(url)全体のコードは下記になります。
from selenium import webdriver
from selenium.webdriver.chrome import service
from selenium.webdriver.support.wait import WebDriverWait
driver_path = 'chromedriver'
chrome_service = service.Service(executable_path=driver_path)
driver = webdriver.Chrome(service=chrome_service)
TIMEOUT = 60
driver.implicitly_wait(TIMEOUT)
wait = WebDriverWait(driver=driver, timeout=TIMEOUT)
url = 'https://google.com'
driver.get(url)これを実行するとGoogleの検索ページが表示されます。
エラーが出る場合は、importやドライバーが正しく設定されているか確認してください。
今回は、Googleの表示ではなく、JPXの日本株一覧が欲しいのでJPXのURLに変更します。
JPXのトップページからクローリングするのはめんどくさいので、直接一覧がダウンロードできるページを表示します。
そのため、urlの部分を下記の様に修正します。
url = 'https://www.jpx.co.jp/markets/statistics-equities/misc/01.html'2021年11月時点では、下記の様に「東証上場銘柄一覧(2021年10月末)としてエクセルがダウンロードできるページが表示されます。

ダウンロード処理
日本株の一覧表をダウンロードするには、下記の赤枠の部分をクリックする必要があります。
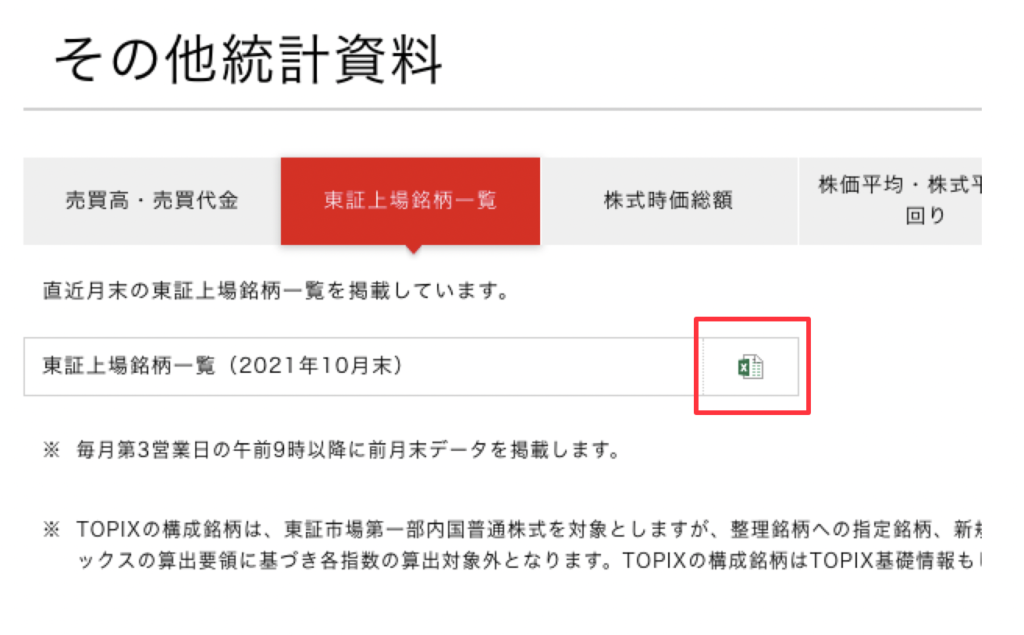
この部分をクリックするには、HTMLの構成などの要素を知る必要があります。
HTMLについては、このページで解説していますので必要であればご確認ください。
-

-
HTML開発の入門!VSCodeのオススメプラグインと基本的な書き方を紹介
私はプログラミング開発を行う時に、VSCodeとIntelliJを併用して使っています。 理由としては、IntelliJがちょこっとしたメモやコードで利用する場合、使い勝手が悪いからです。 カンタンなコードで1ファイルしか開かない場合には、 ...続きを見る
要素を知るためには、chromeを開いて同じ様にJPXのページを開きます。
エクセルのアイコンの部分を右クリックで選択して、メニューの中に「検証」の部分があるので選択します。
下記のキャプチャの様に、右クリックした場所のHTMLの構造がハイライトされて表示されます。

ハイライトされた部分をさらに右クリックします。
そうすると、メニューが表示されるので、「Copy」から「Copy XPath」を選択します。

XPathではなくタグなどの指定でも良かったのですが、XPathの方が確実性があるので使っています。
ここで、取得したXPathを使ってダウンロードをします。
ダウンロードするには、find_element関数を利用します。
find_element関数で取得した要素に対して、クリック関数を使い、クリックのアクションを起こすことでダウンロードが開始されます。
カンタンに説明するとエクセルアイコンの部分をクリックして、株一覧表をダウンロードするって事です。
xpath = '//*[@id="readArea"]/div[4]/div/table/tbody/tr/td/a/img'
el = driver.find_element(by=By.XPATH, value=xpath)
el.click()ここで注意が必要なのが、他のサイトでは「find_element_by_xpath」や「find_element_by_id」などの関数を使って説明されていると思います。
しかし、これはSeleniumのバージョンが4になった事で、非推奨になっています。
そのため、find_element関数を利用して引数のbyの部分で「By.XPATH」や「By.ID」、「By.CLASS_NAME」、「By.TAG_NAME」といった指定をします。
from selenium import webdriver
from selenium.webdriver.chrome import service
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
driver_path = 'chromedriver'
chrome_service = service.Service(executable_path=driver_path)
driver = webdriver.Chrome(service=chrome_service)
TIMEOUT = 60
driver.implicitly_wait(TIMEOUT)
wait = WebDriverWait(driver=driver, timeout=TIMEOUT)
url = 'https://www.jpx.co.jp/markets/statistics-equities/misc/01.html'
driver.get(url)
xpath = '//*[@id="readArea"]/div[4]/div/table/tbody/tr/td/a/img'
el = driver.find_element(by=By.XPATH, value=xpath)
el.click()
このプログラムを実行すると日本株一覧表がダウンロードされます。
ブラウザを閉じる
ダウンロードまで完了しましたが、そのままだとブラウザが開いたままになります。
この状態だと次に開こうとした際に、ブラウザが競合を起こしてエラーになったりします。
それを防ぐために、ブラウザを利用する処理が終わったのであれば、ブラウザを閉じる処理を入れます。
閉じる処理はカンタンで、close関数を呼び出すだけです。
driver.close()これだけだと不十分で、タブなどで複数開いているとブラウザが残ったままになります。
そのため完全に閉じたい場合は、quit関数を呼び出します。
driver.quit()ブラウザを閉じるとダウンロードされない?
ブラウザを閉じる処理をを入れるとダウンロードがされなくなったと思います。
原因としては、ダウンロードが完了するまえにブラウザを閉じているのが原因です。
ここで、waitを使って待機させたいのですが、HTMLの要素が表示されるまでの待機なのでダウンロードについては待機しません。
そのため、ダウンロードが完了するまでブラウザを終了させることを待機させます。
やり方は色々ありますが、ダウンロードにそんな時間がかからないファイルだったのでtime.sleepを利用して対処します。
time.sleep(10)こうする事で、10秒間だけ待ってブラウザを閉じます。
しかしこの処理は、ダウンロードが完了していなくても10秒後には処理を終了するのでネットワークが不安定な場合などでは使えません。
そのため、完了したかどうかの処理を入れる必要があります。
下記は参考として、whileを使って無限ループを作り、1秒おきにダウンロードが完了したファイルがあるかチェックします。
ファイルが存在したら、breakを使って無限ループから抜ける処理をしてブラウザを閉じる処理へ進めるといった手法です。
while True
time.sleep(1)
if ファイルのチェック:
break注意すること

スクレイピング自体は違法ではないのですが、相手のサーバに高負荷をかけたり取得したデータを不正に利用することはダメです。
そのため、迷惑がかからない様に常識の範囲でリクエスト処理をしましょう!
そうでないと、Dos攻撃になってしまって犯罪者になるので注意が必要です。
実際に捕まっている事例もあるので、自身のサイトや管理しているサイト以外では注意が必要です。
今回の日本株一覧を取得するために実行する範囲は、「※毎月第3営業日の午前9時以降に前月末データを掲載します。」とあるため、毎日実行する必要はありません。
毎日実行するとなると迷惑です。
そのため、毎月第3営業日に実行される様にcronなどでスケジュールを管理して実行するようにします。
Windowsだと、ダスクスケジューラを使いMacやLinuxだとcronで良いと思います。
まとめ
PythonのSeleniumを使って、JPXのサイトから日本株一覧表を取得する処理を解説しました。
ChromeやFirefox、Edgeブラウザのドライバの呼び出しから、Selenium4による書き方についてWarningを含め説明していますが注意が必要です。
ほかにも、スクレイピングによる取り扱いについては、逮捕された事例もあるので、取り扱いには気をつけて自己責任でお願いします。
Webスクレイピングをするにしても、HTMLやJavaScriptについて知っておかないとうまく動作させる事ができません。
そのため、下記のUdemyの講座をオススメします。
-

-
【HTML/CSS/JavaScript】フロントエンジニアになりたい人の講座レビュー
この「[HTML/CSS/JavaScript] フロントエンドエンジニアになりたい人の Webプログラミング入門」は、Webのフロントエンジニアを目指す人の講座になります。 WordPressの方でも紹介した、ともすたさんの講座になります ...続きを見る

今後の人生を豊かにする為にキャリアアップのステップとして、自分への投資をしてみませんか?